It has been a long time since the last Hotspots release. I haven't really anticipated this, but clustering and preparing the component to work with large databases proved to be a hard task. I'm happy to say that this 1st development release finally manages to overcome most of the problems related to large database sets. I've made several tests with 10 000 locations and 100 000 locations and things look really good. Your browser is not going to crash and your server is not going to tell you that it is out of memory either!
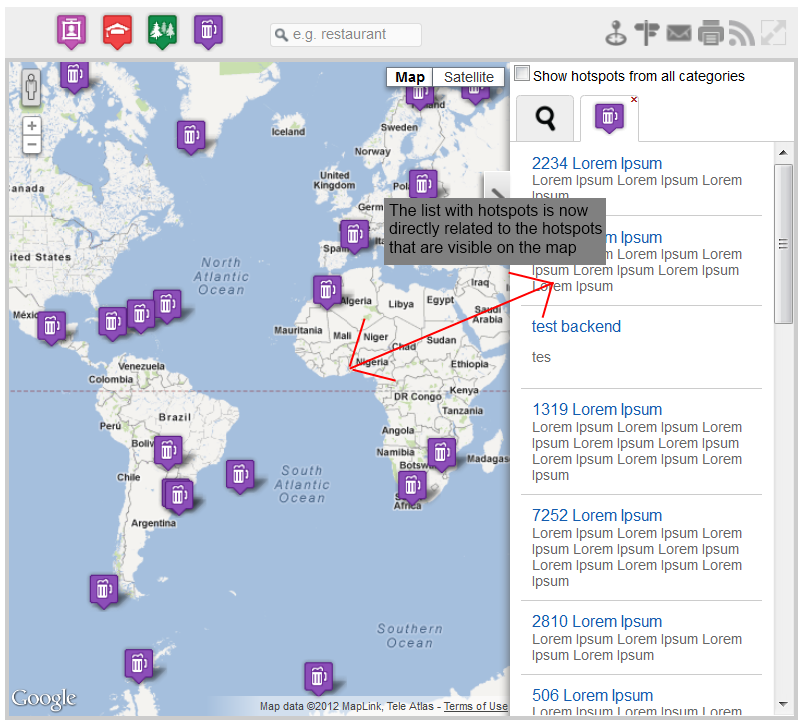
After I've experimented with several clustering algorithms, I've decided to use the server side boundary method. It is a really simple approach that works fine most of the time. When you open the map and it is centered over New York, USA - the component will make an Ajax request sending the boundaries of the map (the furthest northeast and southwest points) to the server and the server will search the database for locations in those boundaries. This is the first difference with Hotspots2. In Hotspots 2.0 the mysql query takes all hotspots in a specific category. Now the new query will return only the results in the viewable area. When the user moves around a new query is executed and we retrieve the results for the new area. But what happens when we have a lot of locations in a specific area? Well, the query will return the first 100 hotspots, but the user will be able to move to the next page which will show the next 100 hotspots etc. Now the list on the right is directly related to the hotspots in the viewable map area. Moving to the second page will change the hotspots on the map. Zooming in, will change the hotspots in the list, etc.
